
Introduction to Partition Switching


Quite often when building a data warehouse we are given the challenge of having to delete existing data before importing the latest and greatest. In an ideal world we would just insert new records and be on our way, but quite often that is not the case. Deleting data isn’t the best option either as by default a DELETE statement takes an exclusive lock on the table it is being executed against. For smaller warehouses you can often work around this by use of the NOLOCK query hint, however, there is a better way to remove data from a table. Partition switching is that its an almost instantaneous schema change (behind the scenes there is actually a pointer change happening inside the filegroup) that equates to selectively truncating data from your table.
There are a few important requirements to be aware of when exporing partition switching:
- The receiving table must already exist in the table, be empty, and have the same column structure, indexes, constraints, and partition scheme the source table.
- Both the source and destination tables or partitions must be in the same file group, the pointer switch which happens behind the scenes is not possible without this.
- There cannot be any XML or Full Text indexes on the source table
- There can be no foreign key relationships between the source and destination tables, nor can there be any foreign key relationships which reference the source table.
- Tables involved in the partition switch can not be sources of replication.
- Triggers cannot be fired during the switch.
- Full details on the rules of partition switching can be found on MSDN
So now that we understand at a high level what partition switching is and its limitation, lets look at how we eliminate data using partition switching. First we are going to make two identical copy of our partitioned table. This can easily be automated using a stored procedure, or if your table structure never changes these tables can be created one time and a truncate can be used instead of a drop at the end of the process.

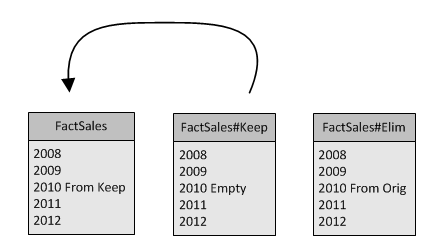
Once the destinations to be used for partition switching are created, the next step is to load new and existing data you wish to keep into one of your duplicates. In my example I am taking 2010 data from a source system using an ETL process and also doing an INSERT INTO … SELECT from FactSales to FactSales#Keep with the 2010 data I do not want to eliminate.

Once all the data we would like to keep is staged into FactSales#Keep the next step is to switch the partition from the orginal table, FactSales, into the elimination table, FactSales#Elim by executing ALTER TABLE FactSales SWITCH PARTITION <source_partition_number_expression> TO FactSales#Elim <target_partition_number_expression>. Since these partitions are in the same file groups SQL Server simply does a pointer switch on the filesystem to achieve this.

Upon swapping out the partition we wish to eliminate we now have an empty partition in the original FactSales table, this allows us to now swap new data in. So we will execute the same switch only this time swapping data in from FactSales#Keep into FactSales.
Once we have successfully loaded FactSales, we can drop the two temporary tables we created at the beginning of the excercise, thus allowing us to replace existing data in our fact table with minimal impact to performance in the warehouse.
